El nacimiento del sistema de defensa antimisiles soviético. "El Burroughs"

Burtsev heredó el amor y el respeto por los prototipos occidentales de su maestro, sí, en principio, a partir de BESM-6, ITMiVT intercambió activamente información con Occidente, principalmente con IBM en EE. UU. y la Universidad de Manchester en Inglaterra (fue esta amistad la que obligó a Lebedev, incluido h., a cabildear por los intereses de la ICL británica, y no de la alemana Robotron en esa memorable reunión de 1969).
Naturalmente, "Elbrus" no podría haber tenido un prototipo, y el propio Burtsev lo admite abiertamente.
La respuesta es inequívoca: "Sí". Antes de comenzar a diseñar una nueva computadora, siempre estudiamos muy cuidadosamente los desarrollos de todo el mundo en esta área.
En ese momento, surgió la cuestión de elevar el nivel del lenguaje de máquina para reducir la brecha entre el lenguaje de alto nivel y el lenguaje de comando para aumentar la eficiencia de pasar programas escritos en un lenguaje de alto nivel.
En esta dirección en el mundo trabajó en tres lugares.
En términos teóricos, el trabajo de Ailif fue el más poderoso: “Principios para construir una máquina básica”, en la Universidad de Manchester en el laboratorio de Kilburn y Edwards se creó la máquina MU-5 (“Universidad de Manchester-5”), y en Burrows, se desarrollaron máquinas para aplicaciones bancarias y militares.
Estuve en las tres empresas, hablé con los principales desarrolladores y tuve los materiales necesarios sobre los principios plasmados en estos desarrollos.
Al diseñar los MVK Elbrus-1 y Elbrus-2, tomamos de los desarrollos avanzados todo lo que nos parecía valioso. Así es como se fabrican y deben desarrollarse todas las máquinas nuevas.
El desarrollo de Elbrus-1 y Elbrus-2 MVK estuvo influenciado por la arquitectura de HP, 5E26, BESM-6 y una serie de otros desarrollos de esa época.
En ese momento, surgió la cuestión de elevar el nivel del lenguaje de máquina para reducir la brecha entre el lenguaje de alto nivel y el lenguaje de comando para aumentar la eficiencia de pasar programas escritos en un lenguaje de alto nivel.
En esta dirección en el mundo trabajó en tres lugares.
En términos teóricos, el trabajo de Ailif fue el más poderoso: “Principios para construir una máquina básica”, en la Universidad de Manchester en el laboratorio de Kilburn y Edwards se creó la máquina MU-5 (“Universidad de Manchester-5”), y en Burrows, se desarrollaron máquinas para aplicaciones bancarias y militares.
Estuve en las tres empresas, hablé con los principales desarrolladores y tuve los materiales necesarios sobre los principios plasmados en estos desarrollos.
Al diseñar los MVK Elbrus-1 y Elbrus-2, tomamos de los desarrollos avanzados todo lo que nos parecía valioso. Así es como se fabrican y deben desarrollarse todas las máquinas nuevas.
El desarrollo de Elbrus-1 y Elbrus-2 MVK estuvo influenciado por la arquitectura de HP, 5E26, BESM-6 y una serie de otros desarrollos de esa época.
Entonces, Burtsev, a diferencia de muchos, admite que no dudó en tomar prestadas generosamente ideas arquitectónicas de sus vecinos e incluso dice dónde buscar colas.
Aprovechemos la generosa oferta y busquemos tres fuentes y tres componentes de Elbrus.

La primera es la monografía de John Iliffe Basic Machine Principles (Macdonald & Co; 1.ª edición, 1 de enero de 1968) y su artículo Elements of BLM (The Computer Journal, volumen 12, número 3, agosto de 1969, páginas 251 a 258), la segunda es una computadora MU5 virtualmente desconocida construida como un experimento en la Universidad de Manchester, y la tercera es una serie Burroughs 700.
¿No es un clon del propio Burroughs?
Vamos a empezar a entender en orden.
Primero, algunos de los lectores pueden haber escuchado el término "arquitectura de von Neumann" que se usa a menudo en el contexto de la jactancia: "aquí hemos diseñado una computadora única que no es de von Neumann". Naturalmente, no hay nada único en esto, aunque solo sea porque las máquinas con arquitectura von Neumann ya no se construían en la década de 1950.
Después de trabajar en el ENIAC (que estaba programado a modo de pestañas, con muchos cables dando vueltas, y no había duda de ningún control de los cálculos por un programa cargado en la memoria, y no había duda) para el siguiente máquina, llamada EDSAC, Mauchly y Eckert propusieron las ideas principales para su diseño.
Son: una memoria homogénea que almacena comandos, direcciones y datos, se diferencian únicamente en cómo se accede a ellos y qué efecto provocan; la memoria está dividida en celdas direccionables, para acceder es necesario calcular la dirección binaria; y finalmente, el principio del control del programa - la operación de la máquina, es una secuencia de operaciones para cargar el contenido de las celdas de la memoria, manipularlas y descargarlas nuevamente en la memoria, bajo el control de comandos que se cargan secuencialmente desde la misma memoria.
Casi todas las máquinas (y solo hubo unas pocas docenas) producidas en el mundo entre 1945 y 1955 obedecieron estos principios, ya que fueron construidas por científicos académicos que estaban muy familiarizados con el Primer Borrador de un Informe sobre el EDVAC, enviado a las universidades por el comisario von Neumann por Herman Heine Goldstine en su nombre.
Naturalmente, esto no podía continuar por mucho tiempo, porque la máquina pura de von Neumann era más bien una abstracción matemática, como una máquina de Turing. Fue útil usarlo con fines científicos, pero las computadoras reales construidas de acuerdo con estas ideas resultaron ser demasiado lentas.
La era de las máquinas von Neumann puras terminó en 1955-1956, cuando la gente comenzó a pensar en tuberías, ejecución especulativa, arquitectura basada en datos y otros trucos similares.
En el año de la muerte de von Neumann, la computadora MANIAC II (Mathematical Analyzer Numerical Integrator and Automatic Computer Model II) se lanzó en el Laboratorio Científico de Los Alamos con 5 lámparas, 190 diodos y 3 transistores.
Funcionaba con datos de 48 bits e instrucciones de 24 bits, tenía 4 palabras de RAM y tenía una velocidad promedio de 096 KIPS.
La máquina fue diseñada por Martin H. Graham, quien propuso una idea fundamentalmente nueva: marcar datos en la memoria con etiquetas apropiadas para una mayor confiabilidad y facilidad de programación.
Al año siguiente, Graham fue invitado por el personal de la Universidad Rice en Houston, Texas, para ayudarlos a construir una computadora tan poderosa como la de Los Álamos. El proyecto de la computadora R1 Rice Institute duró tres años, y en 1961 la máquina estaba lista (luego fue reemplazada por la IBM 7040 estándar para universidades estadounidenses serias e, irónicamente, la Burroughs B5500).
El esquema de decodificación de 2 instrucciones por palabra, como en MANIAC II, le pareció demasiado elegante a Graham, por lo que R1 operaba con palabras de 54 bits con instrucciones de ancho fijo para toda la palabra y tenía una arquitectura de etiquetas similar. La longitud real de la palabra era de 63 bits, de los cuales 7 eran el código de corrección de errores y 2 eran la etiqueta.
El mecanismo de direccionamiento indirecto del R1 era mucho más avanzado que el del IBM 709; de hecho, eran descriptores casi listos para las futuras máquinas Burroughs. Graham también era un ingeniero eléctrico talentoso e inventó un nuevo tipo de celda de diodo de lámpara para el R1, llamada Single Sided Gate, que hizo posible lograr una excelente frecuencia de 1 MHz para esos años. La máquina tenía direcciones de 15 bits, 8 registros de datos/comandos y 8 registros de direcciones.

La primera generación de arquitecturas etiquetadas apareció literalmente inmediatamente después de la muerte de von Neumann. Las máquinas de Ailif y Graham, a la izquierda, una parte del procesador MANIAC II, a la derecha, el propio Ailif está involucrado en la instalación del bastidor principal R1. Foto https://www.sciencephoto.com y https://scholarship.rice.edu
Rice University para USA es algo así como el MINEP soviético, por lo que no es de extrañar que la creación de una computadora (que se iba a utilizar para estudiar la hidrodinámica del petróleo) fuera parcialmente financiada por la Shell Oil Company.
Su curador fue Bob Barton (Robert Stanley Barton), un talentoso ingeniero electrónico. En 1958 tomó un curso de lógica matemática y notación polaca aplicada al álgebra y se fue a trabajar para Burroughs, en 1961 construyó el legendario B5000 basado en la arquitectura de etiquetas de pila.
El mismo británico Ilif trabajó en el software R1. Su equipo creó el sistema operativo SPIREL, el ensamblador simbólico AP1 y el lenguaje GENIE, que se convirtió en uno de los precursores de la programación orientada a objetos. El sistema operativo tenía un mecanismo de asignación de memoria dinámica increíblemente avanzado y un recolector de basura, así como mecanismos de protección de datos y códigos.
Para su sistema operativo, Ailif desarrolló un nuevo mecanismo de direccionamiento de matriz utilizando un vector de punteros a vectores de datos. Esta idea fue tan avanzada sobre el direccionamiento de estilo Fortran (la dirección contiene un paso y un desplazamiento para cada elemento de la matriz) que recibió el nombre del creador, y desde entonces los vectores Ailif se han utilizado en todas partes, desde Ferranti Atlas hasta Java. Python, Ruby, Visual Basic .NET, Perl, PHP, JavaScript, Objective-C y Swift.
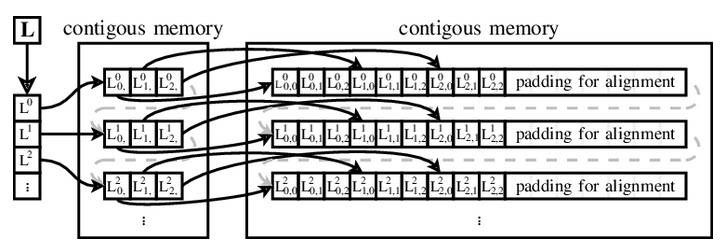
Uso del vector Ailif para abordar una matriz de 3x3 (https://www.researchgate.net)
A fines de la década de 1950, el modelo teórico de la máquina de von Neumann enfrentó un desafío que no tenía una respuesta adecuada (y, por lo tanto, murió por completo).
Las computadoras se volvieron lo suficientemente rápidas como para que una sola persona no pudiera cargarlas con trabajo: apareció el concepto de un mainframe clásico con acceso a la terminal y un sistema operativo multitarea.
No profundizaremos en las complejidades que aguardan a los arquitectos en el camino hacia la multitarea (cualquier libro de texto sensato sobre el diseño de sistemas operativos servirá para esto), solo notamos que la reentrada del código es fundamental para su implementación, es decir, la capacidad de ejecutar varias instancias del mismo programa al mismo tiempo, trabajando sobre diferentes datos, de modo que los datos de un usuario estén protegidos de cambios por parte de otro usuario.
Dejar todos estos problemas completamente en la cabeza del arquitecto del sistema operativo y los programadores del sistema no parecía una muy buena idea: la complejidad del desarrollo del software habría aumentado demasiado (recuerde cómo el proyecto OS / 360 terminó en un fracaso fabuloso, Multics tampoco lo hizo). despegar).
También había una salida alternativa: crear una arquitectura adecuada para la computadora misma.
Fueron estas posibilidades las que consideraron casi simultáneamente los colegas de R1: el practicante Barton, que diseñó el B5000, y el teórico Ailif, que escribió los Principios básicos de las máquinas que tanto inspiraron a Burtsev.
ICL (con la que nunca nos asociamos) lideró el desarrollo de arquitecturas avanzadas de 1963 a 1968 (fue sobre la base del trabajo que se escribió el artículo), Ilif construyó un prototipo de BLM para ellos con métodos de administración de memoria de hardware aún más avanzados que en las máquinas de Burroughs.
La idea principal de Ailif fue un intento de evitar el estándar para otros sistemas (y en esos años lento e ineficiente) mecanismo de intercambio de memoria basado puramente en métodos de software: cambio de contexto (un término de la arquitectura del sistema operativo, que significa, de manera simple, descarga temporal y guardar un proceso en ejecución y cargar e iniciar la ejecución de otro) por el propio sistema operativo. Desde su punto de vista, el enfoque de hardware usando descriptores era mucho más eficiente.
El proyecto BLM se cerró en 1969, pero sus desarrollos se utilizaron parcialmente en la avanzada línea de mainframe ICL 2900 Series, lanzada en 1974 (que bien podríamos haber desarrollado conjuntamente, pero, por desgracia).
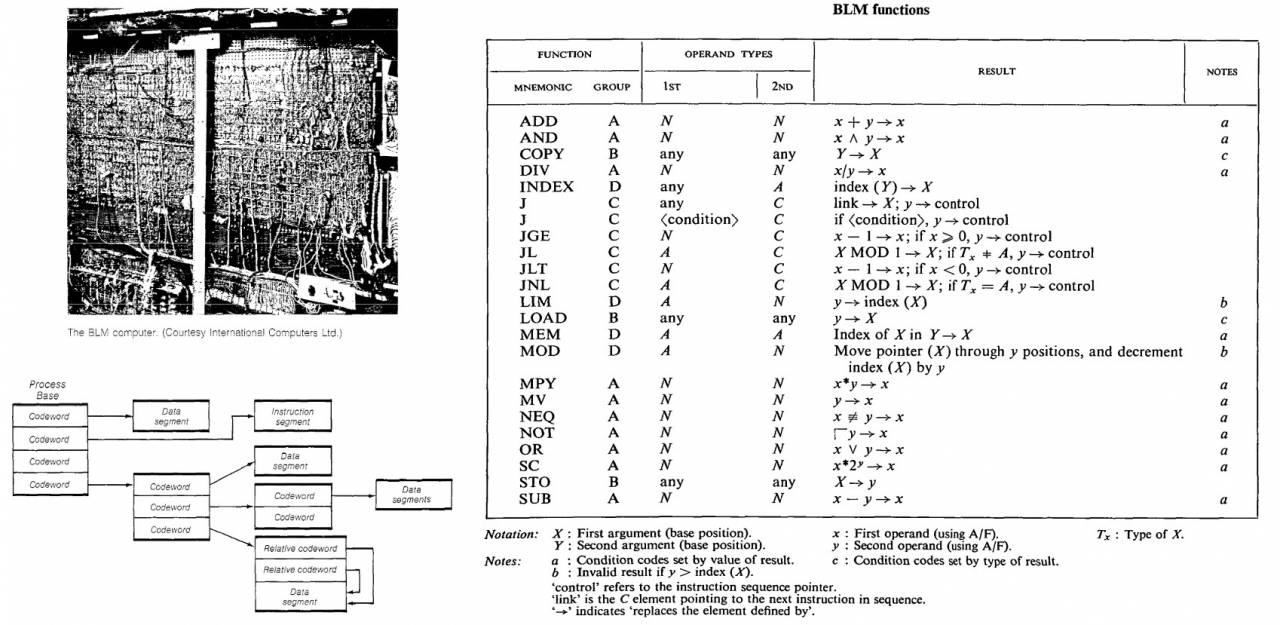
La segunda generación de máquinas de etiquetas y descriptores, desafortunadamente, solo quedó esta foto del libro Descriptor-Based Computer Systems (Levy, Henry M. 1984) de BLM. El sistema de comandos se reproduce del artículo original de Ailif (para que los lectores puedan sumergirse en el problema a raíz de Burtsev).
Naturalmente, el problema de la protección eficaz de la memoria (y, por lo tanto, el tiempo compartido) fue una preocupación en la década de 1960 para casi todos los informáticos y corporaciones.
La Universidad de Manchester no se hizo a un lado y construyó su quinta computadora, llamada MU5.
La máquina fue desarrollada en colaboración con la misma ICL desde 1966, se suponía que la computadora era 20 veces más rápida que Ferranti Atlas en rendimiento. El desarrollo continuó desde 1969 hasta 1974.
MU5 estaba controlado por el sistema operativo MUSS e incluía tres procesadores: el propio MU5, el ICL 1905E y el PDP-11. Todos los elementos más avanzados estaban disponibles: arquitectura de descriptores de etiquetas, memoria asociativa, búsqueda previa de instrucciones, en general, era el pináculo de la tecnología de esos años.
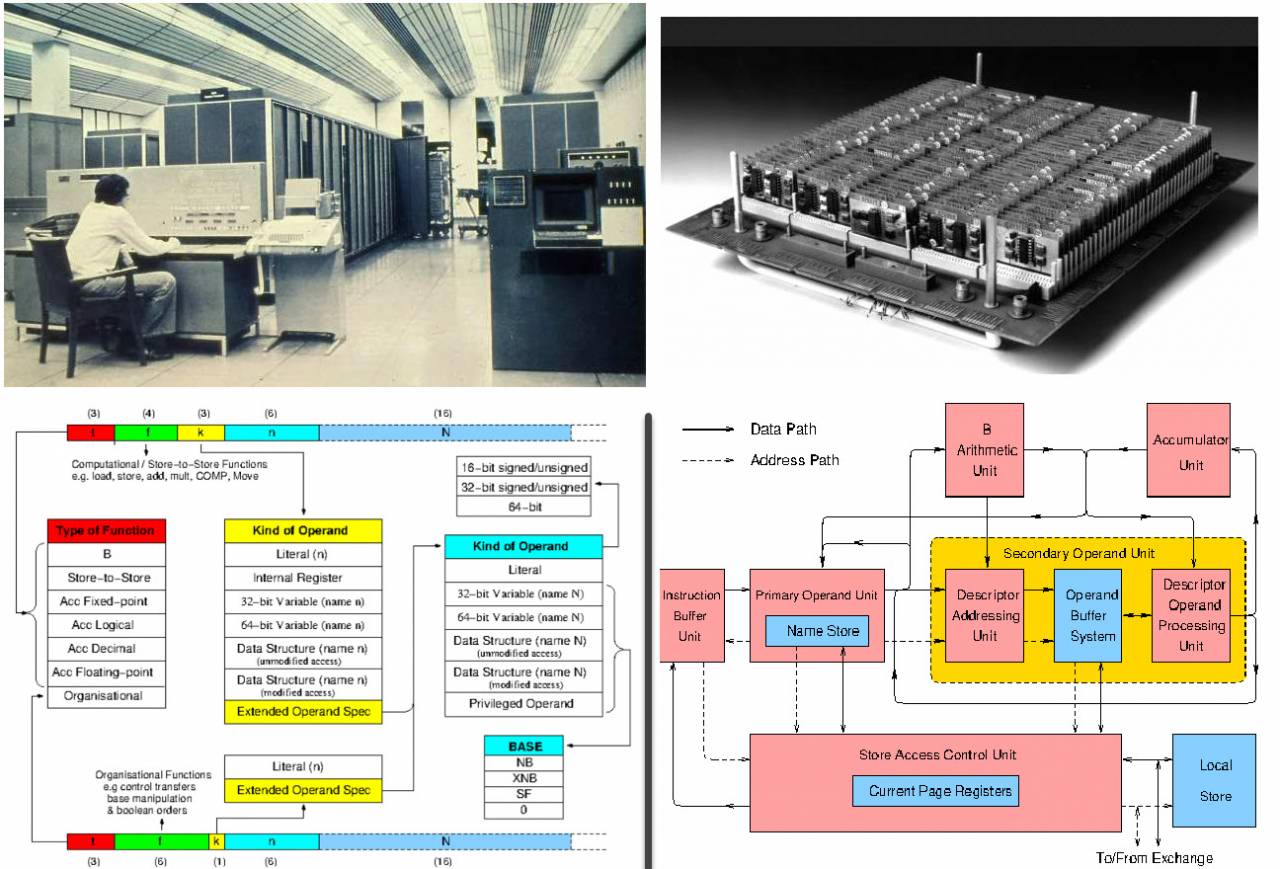
Manchester Machine 5: la única foto, excelente descripción del sistema de comando y la arquitectura (https://ethw.org)
MU5 sirvió como base para la serie ICL 2900 y funcionó en la universidad hasta 1982.
La última computadora de Manchester fue la MU6, que constaba de tres máquinas: la MU66P, una implementación avanzada de microprocesador utilizada como PC; MU66G es una poderosa supercomputadora científica escalar y MU66V es un sistema vectorial paralelo.
Los científicos no han dominado el desarrollo de la arquitectura del microprocesador, MU66G fue creado y trabajado en el departamento de 1982 a 1987, y para MU66V se construyó un prototipo en Motorola 68k con emulación de operaciones vectoriales.

La serie ICL 2900 fue una de las pocas máquinas originales que compitió con bastante fuerza contra la S/360. Para los usuarios británicos de la década de 1980, esta serie está llena de calidez y nostalgia, como para el BESM-6 soviético. Foto http://www.tavi.co.uk y http://www.computinghistory.org.uk
El mayor progreso de las máquinas descriptoras iba a ser el llamado esquema. direccionamiento basado en capacidades (literalmente "direccionamiento basado en capacidades", no tiene una traducción bien establecida al ruso, ya que la escuela doméstica no estaba familiarizada con tales máquinas, en la traducción del libro "Arquitectura informática moderna: en 2 libros" ( Myers GJ, 1985) se denomina muy acertadamente direccionamiento potencial).
El significado del direccionamiento potencial es que los punteros se reemplazan por objetos protegidos especiales que se pueden crear solo con la ayuda de instrucciones privilegiadas ejecutadas solo por un proceso privilegiado especial del kernel del sistema operativo. Esto permite que el kernel controle qué procesos pueden acceder a qué objetos en la memoria sin tener que usar espacios de direcciones separados y, por lo tanto, sin la sobrecarga de un cambio de contexto.
Como efecto indirecto, dicho esquema conduce a un modelo de memoria homogéneo o plano; de ahora en adelante (¡incluso desde el punto de vista de un programador de controladores de bajo nivel!) No hay diferencia de interfaz entre un objeto en la RAM o en el disco, el acceso es absolutamente uniforme, llamando a un objeto protegido. La lista de objetos puede almacenarse en un segmento de memoria especial (como, por ejemplo, en el Plessey System 250, creado en 1969-1972 y que es la encarnación en hardware de un modelo computacional muy esotérico llamado λ-calculus) o codificarse con un poco especial, como en el prototipo IBM System /38.
El Plessey System 250 fue desarrollado para el ejército y como la máquina central de la red de comunicaciones del Departamento de Defensa se utilizó con éxito durante la Guerra del Golfo.
Esta computadora era el pináculo absoluto de la seguridad de la red, una máquina en la que no había superusuarios con privilegios ilimitados como clase, y no había forma de elevar los privilegios de uno a través de la piratería para hacer lo que no se debe hacer.
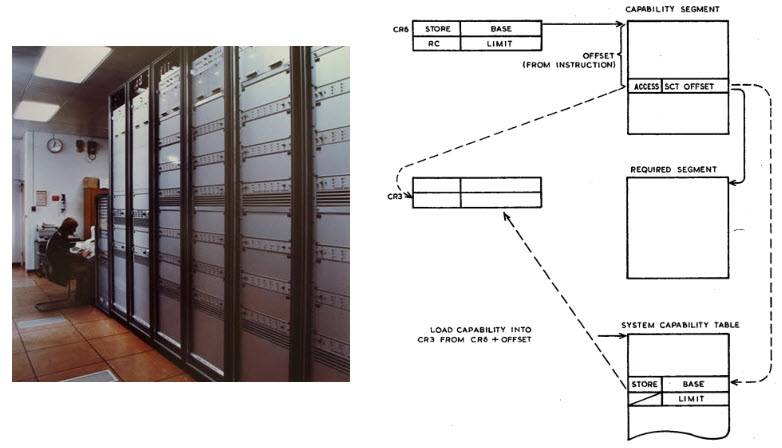
Pless 250 la única foto conocida (de la colección de Kenneth J Hamer-Hodges) y un diagrama del funcionamiento del direccionamiento potencial de la monografía Capability Concept Mechanisms And Structure In System 250, DM England, 1974.
Dicha arquitectura se consideró increíblemente progresista y avanzada en las décadas de 1970 y 1980 y fue desarrollada por muchas empresas y grupos de investigación, las máquinas informáticas CAP (Cambridge, 1970-1977), Flex Computer System (Royal Signals and Radar Establishment, 1970), Three Rivers PERQ (Universidad Carnegie Mellon e ICL, 1980-1985) y el más famoso el fallido microprocesador Intel iAPX 432 (1981).
Es curioso que los iniciadores del 90% de todas las soluciones arquitectónicas más originales y extrañas en las décadas de 1960 y 1970 fueran los británicos (en la década de 1980, los japoneses, con un resultado similar), y no los estadounidenses.
Los científicos británicos (¡sí, esos mismos!) hicieron todo lo posible para mantenerse en la cresta de la ola y confirmar sus calificaciones como destacados teóricos de la informática. La única lástima es que, como en el caso del desarrollo académico soviético de las computadoras, todos estos proyectos fueron fenomenales solo en el papel.
ICL trató desesperadamente de ingresar a los principales fabricantes mundiales de hierro avanzado, pero, por desgracia, no funcionó.
Los estadounidenses al principio pensaron que los colegas anglosajones, dada su contribución pionera a la TI desde la época de Turing, no darían malos consejos, y se quemaron gravemente dos veces, y el Intel iAPX 432 y el IBM System / 38 fallaron miserablemente, lo que provocó un gran giro a mediados de la década de 1980 hacia las arquitecturas de procesadores modernas (fue entonces cuando la escuela estadounidense de ingeniería informática descubrió el principio de las máquinas RISC, que resultó ser tan exitoso desde todos los ángulos que el 99% de las computadoras modernas son de alguna manera construido de acuerdo con estos patrones).

La computadora CAP todavía está en el laboratorio de Cambridge, el prototipo IBM System / 38 y la estación de trabajo Three Rivers PERQ (foto https://en.wikipedia.org y https://www.chiark.greenend.org.uk)
A veces es incluso interesante: ¿qué desarrollos habría lanzado una escuela soviética-británica completa en la década de 1980 con su cultura de producción avanzada, nuestras ideas locas comunes y la capacidad de la URSS para inyectar miles de millones de petrodólares en el desarrollo?
Es lamentable que estas oportunidades se cerraron para siempre.
Naturalmente, la información sobre todos los desarrollos avanzados de los británicos llegó a Burtsev literalmente de primera mano y día tras día, dado que ITMiVT tenía excelentes contactos con la Universidad de Manchester (desde principios de la década de 1960 y trabajo en BESM-6), y con firma ICL, con la que Lebedev tanto deseaba hacer una alianza. Sin embargo, Burroughs fue la única implementación comercial de máquinas descriptoras de etiquetas.
¿Qué se puede decir sobre el trabajo de Burtsev con esta máquina?
Las increíbles aventuras de Burroughs en Rusia
La informática soviética era un área extremadamente cerrada, para muchas máquinas no hay fotografías, descripciones sensatas (sobre la arquitectura de la Kitovskaya M-100, por ejemplo, nada se sabe realmente hasta ahora), y en general aguardan sorpresas a cada paso (como el descubrimiento en la década de 2010 Computadora "Volga", cuya existencia ni siquiera sospecharon Revich, Malinovsky y Malashevich, quienes realizaron docenas de entrevistas y escribieron libros basados en ellos).
Pero en un área en particular había más silencios y secretos que incluso en los vehículos militares. Estas son referencias a computadoras americanas que funcionaban en la Unión.
Este tema era tan desagradable que uno podría tener la impresión de que, aparte del conocido CDC 6500 en Dubna, no había computadoras estadounidenses en la URSS como clase.
Incluso la información sobre CYBER 170 y 172 tuvo que ser extraída poco a poco (¡y había HP 3000 que estaban en la Academia de Ciencias de la URSS y un montón de otros!), pero la presencia de un Burroughs real en vivo en la Unión fue considerada por muchos a ser un mito.
Ni una sola fuente, entrevista, foro o libro en ruso contiene siquiera una línea dedicada al destino de estas máquinas en la URSS. Sin embargo, como siempre, nuestros amigos occidentales saben mucho más sobre nosotros que nosotros mismos.
Como resultado de búsquedas cuidadosas, se estableció que Burroughs era muy querido en el Bloque Social y se usaba con fuerza, aunque las fuentes domésticas aquí tenían agua en la boca.
Afortunadamente, hay suficientes fanáticos de esta arquitectura en los EE. UU. que saben todo sobre ella, incluido el número completo de instalaciones de cada modelo de sus mainframes, hasta los números de serie. Resumieron esta información en una tabla, que generosamente compartieron, y el documento también incluye las fuentes de información para cada envío de computadoras Burroughs a los países del Pacto de Varsovia.
Entonces, pasemos al libro Economic Statecraft during the Cold War: European Responses to the US Trade embargo, que nos revela los secretos de las adquisiciones soviéticas.
A principios de octubre de 1969, un grupo de estudio del personal interinstitucional de la administración... En ese momento, las corporaciones informáticas estadounidenses comenzaron a vender en Europa del Este. La Corporación Burroughs de Detroit instaló cuatro de sus grandes computadoras B5500 en Checoslovaquia y una en Moscú que eran equivalentes a la gama media de las computadoras de IBM. Los programadores y el personal de mantenimiento soviéticos fueron capacitados en la planta de Detroit.
¡Oh, cómo, en 1969, Burroughs B5500 no solo se instaló en Moscú, sino que los especialistas soviéticos también lograron realizar una pasantía en la fábrica de la compañía en Detroit!
Otros 4 autos fueron vendidos a Checoslovaquia por orden del gobierno, desafortunadamente, no se sabe dónde se instalaron y qué hicieron, pero obviamente no en las universidades, la columna "usuario" en la tabla indica "gobierno". El B6700 más potente (¡luego actualizado a B7700!) Se vendió en la RDA y se usó en la Universidad de Karlsruhe.
Otros intentos de aclarar la información sobre las entregas a Moscú nos obligaron a contactar al Museo de Ingeniería, Comunicaciones y Computación del Suroeste (Arizona, EE. UU.).
En su sitio web, puede encontrar una nota al pie de un artículo de 1982 de Alistair Mayer de Computer Architecture News de ACM (Alastair JW Mayer, The Architecture of the Burroughs B5000 – 20 Years Later and Still Ahead of the Times), una carta del ingeniero Rea Williams ) del equipo de instalación y soporte de Burroughs Corporation:
Pues allá por cuando, no recuerdo el año exacto, allá por 1973… Burroughs vendió un B6500 (B6700) al Ministerio del Petróleo de Rusia. Era un sistema muy especial con impresoras cirílicas, lectores de cintas de papel especiales y otras cosas muy especiales. Esto fue durante la guerra fría, pero nosotros (Burroughs) teníamos un permiso especial para suministrar el sistema. Participé en el sistema "ride out" en la planta de City of Industry. Glen estaba con nuestra organización TIO y fue a Rusia para ayudar a instalar y capacitar a la gente local para mantenerla. Contó historias de la GRU o lo que fuera desconfiando de sus juegos de cartas porque pensaban que los chicos de Burroughs estaban "colaborando" o algo así y tenían que dejar las puertas de sus habitaciones abiertas. Grandes historias, ojalá pudiera recordarlas todas. Entonces, al final me dio el pin. Tengo algunas otras cosas que te contaré más adelante.
Por cierto, en honor a tal evento, los soviéticos emitieron insignias conmemorativas con el emblema de Burroughs y la inscripción "Barrows" y las distribuyeron a los participantes del proyecto. La insignia original de Williams adorna el título de este artículo.
Entonces, la industria petrolera soviética (generalmente paralela a toda la anarquía que estaba ocurriendo alrededor de nuestras computadoras militares y científicas), siendo extremadamente influyente, rica e infinitamente alejada de todos los enfrentamientos de la Academia y el partido, no queriendo contentarse con computadoras domésticas (y absolutamente sin querer algo allí, ordenar a alguien de los institutos de investigación soviéticos y esperar hasta que después de diez años de enfrentamientos todos fallen), lo tomó con calma y se compró lo mejor que pudo: un excelente B6700. Incluso llamaron a un equipo de instalación dentro de la corporación para que la preciada máquina funcionara correctamente.
No es de extrañar que este episodio, que muestra claramente cómo personas realmente serias (no olvidemos que los trabajadores petroleros trajeron al país la mayor parte del dinero, que los militares y académicos luego gastaron en sus juegos) trataron los autos domésticos, intentaron olvidar más fuerte.

Burroughs B6700 de la Universidad de Tasmania y lo último en la línea de Burroughs Large Systems - el gran B7900 (http://www.retrocomputingtasmania.com, https://pretty-little-fools.tumblr.com)
Señalamos dos hechos interesantes.
En primer lugar, a pesar de que todo el mundo conoce a Burroughs principalmente por el suministro de sus mainframes (como patrón oro de la arquitectura segura) a la Reserva Federal estadounidense, también tenían órdenes militares (aunque mucho menos que IBM y Sperry, que durante la Segunda Guerra Mundial). Guerra no lograron establecer contactos con el gobierno).
Y además, sus coches eran muy, muy aficionados a las universidades. Incluso se puede decir: lo adoraron en todo el mundo: en Gran Bretaña, Francia, Alemania, Japón, Canadá, Australia, Finlandia e incluso Nueva Zelanda, se instalaron más de cien mainframes Burroughs de diferentes líneas. Arquitectónicamente (y en términos de estilo), Burroughs era la Apple de la gran computadora.
Sus máquinas eran robustas y fenomenalmente confiables, costosas, poderosas, venían como un kit absoluto con todo el software y los paquetes de software preinstalados y configurados, la arquitectura era cerrada, diferente a cualquier cosa en el mercado.
Fueron amados por intelectuales de todas las tendencias porque Burroughs (al igual que la Macintosh de la era dorada) simplemente se conectan y funcionan. Según los estándares de los mainframes de aquellos años, incluso tan exitosos como el S/360, era increíblemente genial.
Y, por supuesto, diferían en diseño, terminales convenientes de marca, sistema de carga de discos original y muchas otras cosas. También notamos que en sus años fue, aunque no una supercomputadora, sino una poderosa máquina de trabajo que producía alrededor de 2 MFLOPS, varias veces más poderosa que cualquier cosa que tuviera la URSS en ese momento.
En general, las universidades los amaban con razón, por lo que usar Burroughs como una supercomputadora científica en la Unión sería una decisión completamente justificada. Una ventaja adicional fue el soporte de hardware para Algol, un lenguaje que se consideraba, en primer lugar, el estándar de oro de la educación superior (especialmente en Europa) y, en segundo lugar, extremadamente lento en cualquier otra arquitectura.
Algol (cuyo soporte total no aparecía en máquinas puramente domésticas) merecidamente se consideraba el estándar de la programación estructurada académica clásica. No sobrecargado con construcciones esotéricas como PL / I, no tan anárquico como Pure C, muchas veces más conveniente que Fortran, mucho menos alucinante que LISP y (Dios no lo quiera) Prolog.
Antes del advenimiento del concepto OOP, no se creó nada más perfecto y más conveniente, y Burroughs fueron las únicas máquinas en las que no disminuyó la velocidad.
Otro hecho merece gran atención.
KoCom categóricamente no nos permitió comprar arquitecturas avanzadas, incluso las restricciones en las estaciones de trabajo potentes de la década de 1980 se levantaron solo después del colapso de la URSS, tuvimos que luchar ferozmente por CDC, CYBER se vendió con un crujido (como ya mencionamos, el director de Control Data ya estaba siendo investigado por el Congreso sobre actividades antiamericanas), y se instalaron varias máquinas con objetivos en interés de los Estados Unidos.
Se nos entregó CYBER del Centro Hidrometeorológico para ayudar con los datos sobre el clima del Ártico, y se nos entregó CYBER LIAN a cambio de la promesa de desarrollar conjuntamente computadoras recursivas.
Como resultado, por cierto, se vendieron en vano, el trabajo conjunto no funcionó.
El verdadero autor de la idea, Torgashov, fue rápidamente empujado al infierno por sus jefes, tan pronto como la fama y el dinero de trabajar con los Yankees asomaron en el horizonte. Los estadounidenses llegaron, intentaron obtener algunos gestos en desarrollo de los jefes, quienes tenían dificultades para imaginar cómo funcionan las máquinas ordinarias, finalmente escupieron en todo y se fueron.
Entonces, la URSS perdió otra oportunidad de ingresar al mercado mundial.
Pero nos entregan Burroughs frescos sin pestañear, ni el CoCom ni el Congreso se oponen, no hay quejas. Esto sólo puede justificarse, de nuevo, por los intereses de las grandes empresas.
Se lo vendieron a los trabajadores petroleros con la garantía de que obviamente no renunciarían a su encanto a los militares, ellos mismos lo necesitan, pero es muy beneficioso para ambas partes ser amigos de la industria petrolera soviética.
También notamos que comenzaron a vendernos Burroughs solo en los años de Brezhnev, cuando la intensidad de la Guerra Fría disminuyó significativamente, como escribimos en artículos anteriores. Al mismo tiempo, los astutos yanquis no tenían prisa por animar a sus oponentes con tecnologías puramente militares (como el más potente CDC 6600 o Cray-1), pero no les importaba apoyar el negocio soviético.
Sin embargo, la disertación de doctorado en administración de empresas de Peter Wolcott de la Universidad de Arizona Tecnología avanzada soviética: el caso de la computación de alto rendimiento, publicada en 1993, establece que el B6700 se instaló en Moscú en 1977 (es decir, todas las aprobaciones y la entrega tomó un total de 4 años!).
La mayor parte del trabajo de diseño preliminar del Elbrus se completó entre 1970 y 1973, cuando Burtsev pudo ver un automóvil vivo solo en los EE. UU. (Desafortunadamente, no hay información sobre cuándo fue exactamente allí).
En ese momento, los ingenieros de ITMiVT solo tenían acceso a la documentación general del B6700: la arquitectura de instrucciones y los diagramas de bloques de la máquina. Wolcott escribe que recibieron información más detallada en 1975-1976 (aparentemente, después del viaje de Burtsev, quien trajo un montón de papeles), lo que condujo a algunas mejoras y cambios en la estructura de Elbrus.
Finalmente, en 1977, los desarrolladores estudiaron los Burroughs de Moscú en detalle, lo que condujo a otra ola de actualizaciones, probablemente con esto, incluido el proceso continuo de realizar cambios en los documentos que ya estaban en producción.
Por ello, podemos garantizar que la inspiración visitó a Burtsev, claramente bajo la influencia, en primer lugar, de las obras del británico, con las que pudo familiarizarse a mediados de los años sesenta. Y sí, en aquellos días, la dirección de las máquinas de descriptores de etiquetas era considerada “en términos teóricos, la más poderosa”, es decir, era apoyada, como la más prometedora, por casi toda la informática académica en Gran Bretaña.
En este sentido, el trabajo sobre Elbrus estaba en la línea de la investigación más avanzada en ese momento, y no fue culpa de los académicos británicos que a mediados de la década de 1980 el mundo girara en una dirección completamente diferente.
También notamos que, según los artículos teóricos, el equipo de Burtsev no logró construir un automóvil, solo la familiarización con la documentación sobre los Burroughs en vivo les permitió descubrir completamente cómo funciona esto.
Comparación de arquitectura
Toda la línea de Burroughs Large Systems Group se construyó sobre una única arquitectura B5000. Las designaciones de las máquinas eran extremadamente extravagantes. Los últimos tres dígitos indicaron la generación de máquinas, y el primero, el número de serie en términos de potencia en la generación.
Así, teníamos disponible la serie 000 (el único representante es el ancestro del B5000), luego no se usaban los números del 100 al 400 (pasaban a Sistemas Medianos y Sistemas Pequeños), y la siguiente serie recibía el índice 500. Tenía tres computadoras, divididas por potencia: más simple (B5500), más complicada (B6500) y, en teoría, la más poderosa (B8500).
Sin embargo, el B6500 ya se estancó y, como resultado, la serie se quedó estancada en el modelo más joven. El siguiente número 600 también se eliminó (para no confundirlo con CDC), y así aparecieron las líneas B5700, B6700 y B7700.
Se diferenciaban en la cantidad de memoria, la cantidad de procesadores y otros detalles arquitectónicos no principales. Finalmente, la última línea fue la serie 800 de dos modelos (B6800 y B7800) y la 900 de tres (B5900, B6900 y B7900).
Todo el código escrito para los sistemas grandes es reentrante listo para usar, y el programador del sistema no tiene que hacer ningún esfuerzo adicional para esto. En pocas palabras, el programador simplemente escribió el código, sin pensar en absoluto que podría funcionar en modo multiusuario, el sistema tomó el control.
No había ensamblador, el lenguaje del sistema era un superconjunto de ALGOL, el lenguaje ESPOL (Lenguaje orientado a problemas de sistemas ejecutivos), en el que se escribieron el kernel del sistema operativo (MCP, Master Control Program) y todo el software del sistema.
Fue reemplazado por el más avanzado NEWP (Nuevo lenguaje de programación ejecutiva) en la serie 700. Se desarrollaron dos extensiones más para un trabajo eficiente con datos: DCALGOL (ALGOL de comunicaciones de datos) y DMALGOL (ALGOL de gestión de datos), y apareció un lenguaje de línea de comandos independiente WFL (Lenguaje de flujo de trabajo) para una gestión eficiente de MCP.
Los compiladores Burroughs COBOL y Burroughs FORTRAN también se escribieron en ALGOL y se optimizaron cuidadosamente para tener en cuenta todos los matices de la arquitectura, por lo que las versiones para sistemas grandes de estos lenguajes fueron las más rápidas del mercado.
La profundidad de bits de las grandes máquinas Burroughs era convencionalmente de 48 bits (+3 bits de etiqueta). Los programas consistían en entidades especiales: sílabas de 8 bits, que podían ser una llamada a un nombre, un valor o crear un operador, cuya longitud variaba de 1 a 12 sílabas (esta fue una innovación significativa de la serie 500, el classic B5000 usaba instrucciones fijas de 12 bits de longitud).
El lenguaje ESPOL en sí tenía menos de 200 declaraciones, todas las cuales encajaban en sílabas de 8 bits (incluidos los poderosos operadores de edición de líneas y similares, sin ellos solo había 120 instrucciones). Si eliminamos los operadores reservados para el sistema operativo, como MVST y HALT, el conjunto comúnmente utilizado por los programadores de nivel de usuario sería inferior a 100. Algunos operadores (como Name Call y Value Call) podrían contener pares de direcciones explícitos, otros usaron una pila de ramificación avanzada.
Burroughs no tenía registros disponibles para el programador (para la máquina, la parte superior de la pila y el siguiente se interpretaban como un par de registros), respectivamente, no había necesidad de que los operadores trabajaran con ellos y varios sufijos/prefijos tampoco eran necesarios para indicar opciones para realizar operaciones entre registros, ya que todas las operaciones se aplicaban en la parte superior de la pila. Esto hizo que el código fuera extremadamente denso y compacto. Muchos operadores eran polimórficos y cambiaban su trabajo de acuerdo con los tipos de datos definidos por las etiquetas.
Por ejemplo, en el conjunto de instrucciones de sistemas grandes, solo hay una instrucción ADD. Un ensamblador moderno típico contiene varios operadores de suma para cada tipo de datos, como add.i, add.f, add.d, add.l para enteros, flotantes, dobles y largos. En Burroughs, la arquitectura solo distingue entre números de precisión simple y doble: los números enteros son simplemente reales con exponente cero. Si uno o ambos operandos tienen la etiqueta 2, se realiza una suma de precisión doble; de lo contrario, la etiqueta 0 indica precisión simple. Esto significa que el código y los datos nunca pueden ser incompatibles.
Trabajar con la pila en Burroughs se implementa muy bien, no aburriremos a los lectores con detalles, solo confíe en nuestra palabra.
Solo notamos que las operaciones aritméticas tomaron una sílaba, las operaciones de pila (NAMC y VALC) tomaron dos, las ramas estáticas (BRUN, BRFL y BRTR) tomaron tres y los literales largos (por ejemplo, LT48) tomaron cinco. Como resultado, el código era mucho más denso (más precisamente, tenía más entropía) que en la arquitectura RISC moderna. El aumento de la densidad redujo los errores de caché de instrucciones y, por lo tanto, mejoró el rendimiento.
De la arquitectura del sistema, notamos SMP - multiprocesador simétrico hasta 4 procesadores (esto es en la serie 500, a partir de la serie 800, SMP ha sido reemplazado por NUMA - Acceso a memoria no uniforme).
Los Burroughs fueron generalmente pioneros en el uso de múltiples procesadores conectados por un bus de alta velocidad. La línea B7000 podía tener hasta ocho procesadores, siempre que al menos uno de ellos fuera un módulo de E/S. Se suponía que el B8500 tendría 16, pero finalmente se canceló.
A diferencia de Seymour Cray (y Lebedev y Melnikov), los ingenieros de Burroughs desarrollaron las ideas de una arquitectura masivamente paralela, conectando muchos procesadores paralelos relativamente débiles con una memoria común, en lugar de usar uno vectorial súper poderoso.
Como se muestra historia Este enfoque terminó siendo el mejor.
Además, los sistemas grandes fueron las primeras máquinas apiladoras del mercado y sus ideas formaron más tarde la base del lenguaje Forth y las computadoras HP 3000. pila de saguaro (este es un cactus así, por lo que llaman una pila con ramas). Todos los datos se almacenaban en la pila, a excepción de los arreglos (que podían incluir tanto cadenas como objetos), se les asignaban páginas en la memoria virtual (primera implementación comercial de esta tecnología, por delante de S/360).
Otro aspecto bien conocido de la arquitectura de Grandes Sistemas fue el uso de etiquetas. Este concepto apareció originalmente en el B5000 para aumentar la seguridad (donde la etiqueta simplemente separaba el código y los datos, como el bit NX moderno), a partir de la serie 500, el papel de las etiquetas se amplió significativamente. Se les asignaron 3 bits en lugar de 1, por lo que había un total de 8 opciones de etiquetas disponibles. Algunos de ellos son: SCW (palabra de control de software), RCW (palabra de control de retorno), PCW (palabra de control de programa), etc. La belleza de la idea era que el bit 48 era de solo lectura, por lo que las etiquetas impares denotaban palabras de control que el usuario no podía cambiar.
La pila es muy buena, pero ¿cómo trabajar con objetos que por su estructura no encajan en ella, por ejemplo, cadenas? Después de todo, necesitamos soporte de hardware para trabajar con arreglos.
Muy simple, Large Systems usa descriptores para esto. Los descriptores, como sugiere el nombre, describen las áreas de almacenamiento de las estructuras, así como las solicitudes y resultados de E/S. Cada descriptor contiene un campo que indica su tipo, dirección, longitud y si los datos se almacenan en la tienda. Naturalmente, están marcados con su propia etiqueta. La arquitectura de los descriptores de Burroughs también es muy interesante, pero no entraremos en detalles aquí, solo notamos que la memoria virtual se implementó a través de ellos.
La diferencia entre Burroughs y la mayoría de las demás arquitecturas es que utilizan memoria virtual paginada, lo que significa que las páginas se paginan en fragmentos de tamaño fijo, independientemente de la estructura de la información que contengan. La memoria virtual B5000 funciona con segmentos de diferentes tamaños, que se describen mediante descriptores.
En ALGOL, los límites de los arreglos son completamente dinámicos (en este sentido, Pascal con sus arreglos estáticos es mucho más primitivo, ¡aunque esto está solucionado en la versión de Burroughs Pascal!), y en los sistemas grandes, un arreglo no se asigna manualmente cuando se declara. , pero automáticamente cuando se accede a él.
Como resultado, las llamadas al sistema de asignación de memoria de bajo nivel, como el legendario malloc en C, ya no son necesarias. un montón de rutina compleja y aburrida. De hecho, los sistemas grandes son máquinas que admiten la recolección de basura a la JAVA, ¡y en hardware!
Irónicamente, muchos usuarios de Burroughs, que cambiaron a él en las décadas de 1970 y 1980 y trasladaron sus (¡aparentemente correctos!) programas del lenguaje C, encontraron muchos errores en ellos relacionados con desbordamientos de búfer.
El problema de las restricciones físicas en la longitud del descriptor, que no permitía direccionar directamente más de 1 MB de memoria, se resolvió elegantemente a fines de la década de 1970 con la llegada del mecanismo ASD (Advanced Segment Descriptors), que hizo posible asigne terabytes de RAM (en las computadoras personales, esto apareció solo a mediados de la década de 2000 - X).
Además, los llamados. Las interrupciones de p-bit, lo que significa que se ha asignado un bloque de memoria virtual, se pueden utilizar en Burroughs para el análisis de rendimiento. Por ejemplo, de esta manera puede notar que el procedimiento que asigna una matriz se llama constantemente. El acceso a la memoria virtual reduce drásticamente el rendimiento, razón por la cual las computadoras modernas comienzan a funcionar más rápido si conecta otro chip RAM.
En las máquinas de Burroughs, el análisis de las interrupciones de p-bit nos permitió encontrar un problema sistémico en el software y equilibrar mejor la carga, lo cual es importante para los mainframes que funcionan las 24 horas del día, los 7 días de la semana durante todo el año. En el caso de máquinas grandes, ahorrar incluso un par de minutos de tiempo por día se convirtió en un buen aumento final de la productividad.
Finalmente, las etiquetas, al igual que las etiquetas, fueron responsables de un aumento significativo en la seguridad del código. Una de las mejores herramientas que tiene un pirata informático para comprometer los sistemas operativos modernos es un desbordamiento de búfer clásico. El lenguaje C, en particular, utiliza la forma más primitiva y propensa a errores de marcar el final de las líneas, utilizando un byte nulo como señalizador de final de línea en el propio flujo de datos (en general, tal descuido distingue muchas cosas creadas). , se podría decir, en un estilo académico, es decir, personas inteligentes que no tienen, sin embargo, calificaciones especiales en el campo del desarrollo).
En Burroughs, los punteros se implementan como inodos. Durante la indexación, el hardware los verifica en cada incremento/decremento para evitar sobrepasar los límites de los bloques. Durante cualquier lectura o copia, los bloques de origen y de destino están controlados por descriptores de solo lectura para mantener la integridad de los datos.
Como resultado, una clase importante de ataques se vuelve imposible en principio, y muchos errores en el software pueden detectarse incluso en la etapa de compilación.
No es de extrañar que Burroughs sea tan querido por las universidades. En las décadas de 1960 y 1980, los programadores calificados, por regla general, trabajaban en grandes corporaciones, los científicos escribieron software para ellos mismos, como resultado, los sistemas grandes facilitaron enormemente su trabajo, lo que hizo imposible arruinar fundamentalmente cualquier programa.
Burroughs ha influido en una gran cantidad de tecnologías.
Como dijimos, la línea HP 3000, y también sus legendarias calculadoras todavía en uso hoy en día, se inspiraron en la pila de sistemas grandes. Los servidores tolerantes a fallas de Tandem Computers también llevaron la impronta de esta obra maestra de la ingeniería. Además de Forth, las ideas de Burroughs influyeron significativamente en Smalltalk, el padre de todo OOP y, por supuesto, en la arquitectura de la máquina virtual JAVA.
¿Por qué se extinguieron esas grandes máquinas?
Bueno, en primer lugar, no se extinguieron de inmediato, la clásica arquitectura real de descriptor de etiquetas de Burroughs continuó continuamente en la línea de mainframe UNISYS hasta 2010 y solo luego perdió terreno frente a los servidores en el banal Intel Xeon (con el que incluso IBM es terriblemente difícil de competir). ). El desplazamiento ocurrió por una razón banal, que mató a todos los demás autos exóticos de la década de 1980.
En la década de 1990, los procesadores de propósito general como el DEC Alpha y el Intel Pentium Pro se impulsaron a un rendimiento tan tremendo que muchos trucos arquitectónicos elaborados se volvieron innecesarios. SPARCserver-1000E en un par de SuperSPARC-II de 90 MHz venció a Elbrus de todas las opciones como una tortuga divina.
La segunda razón por la que Burroughs se vino abajo fueron los mismos problemas que casi matan a Apple en la década de 1980, exacerbados por la escala del negocio de mainframe. Sus máquinas eran tan complejas que eran extremadamente costosas y requerían mucho tiempo para desarrollarlas, por lo que básicamente solo hicieron versiones ligeramente mejoradas de la misma arquitectura a lo largo de la década de 1970. Tan pronto como Burroughs trató de mudarse a otro lugar (como en el caso del B6500 o B8500), el proyecto comenzó a fallar, absorbió dinero a la velocidad de un agujero negro y finalmente se canceló (como el fallido Apple III y Lisa). .
La escala de mainframe significó que Burroughs vendiera computadoras por millones de dólares con un mantenimiento increíblemente costoso. Por ejemplo, se suponía que el B8500 tendría 16 procesadores, pero el costo estimado de una configuración incluso con tres superaba los $14 millones, por lo que se rescindió el contrato para su suministro.
Además del costo fenomenal de las propias máquinas, los mainframes más antiguos de la empresa exigían una gran cantidad de dinero para soporte. El paquete anual de mantenimiento, servicio y todas las licencias para todo el software, en el caso del modelo B7800 de gama alta, cuesta alrededor de $ 1 millón al año, ¡no todos pueden permitirse ese lujo!
Me pregunto si los petroleros soviéticos compraron un servicio completo o repararon ellos mismos sus Burroughs, con una palabra fuerte y un mazo.
Así que el negocio de Burroughs siempre cojeaba, sin la escala y la fuerza de IBM. No podían fabricar autos baratos debido a la complejidad del desarrollo, y los compradores de autos caros, dada la batalla activa con los competidores, no eran suficientes para aumentar las ganancias y la oportunidad de invertir dinero extra en el desarrollo y reducir los precios, haciendo que los autos fueran más competitivos.
Sperry UNIVAC sufrió los mismos problemas, eventualmente en 1986 las dos corporaciones se fusionaron para sobrevivir y formar UNISYS, que ha estado produciendo mainframes desde entonces.
Además de las arquitecturas mencionadas, Burtsev realmente usó la experiencia de 5E26 y 5E92b en términos de control de errores de hardware. Ambas computadoras eran capaces de detectar y corregir cualquier error de un bit por hardware, y en el proyecto Elbrus este principio se llevó a nuevas alturas.
Entonces, estamos esperando la respuesta a la pregunta más fascinante: ¿Era Elbrus El Burrows?
Como recordamos, Ailif abandonó el modelo clásico de von Neumann, la máquina como un almacenamiento lineal de instrucciones y datos. La pila saguaro en Burroughs era una estructura de árbol que reflejaba la ejecución de código paralelo y la jerarquía de procesos en un entorno de multiprogramación multiusuario. Tenga en cuenta, por cierto, que ALGOL, con su estructura jerárquica de bloques, encaja perfectamente en la pila, razón por la cual su implementación en Grandes Sistemas fue tan exitosa.
Esta filosofía de diseño integrado fue promovida de manera no trivial por los arquitectos del sistema Elbrus, quienes la elevaron a un nuevo nivel. En particular, en lugar de varios lenguajes especializados, un grupo de desarrolladores de ITMiVT creó un El-76 universal similar a Algol.
Las novedades arquitectónicas no terminaron ahí.
En la siguiente tabla se muestra una comparación directa de las máquinas, la antigua B6700 en su conjunto se ve bien en el contexto de una computadora 17 años más joven.
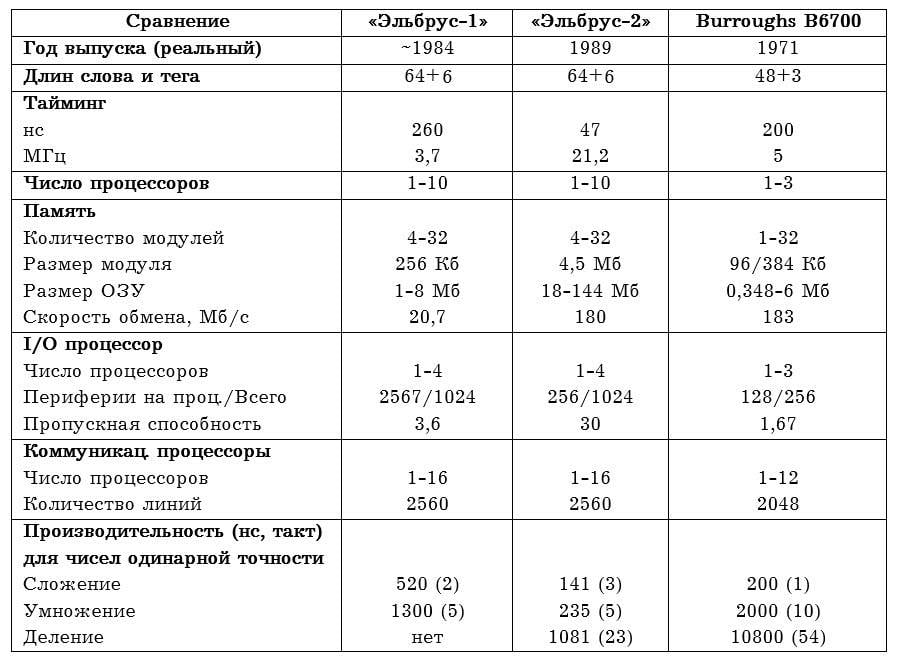
De lo interesante: a diferencia del B6700, Elbrus era monstruosamente enorme.
La primera versión ocupaba 300 m1. m en un solo procesador y 270 sq. m en una configuración de 10 procesadores, y el segundo, respectivamente 420 y un increíble 2 sq. m, quitándole así los laureles al ordenador más grande de la historia al propio IBM AN/FSQ-260 Project SAGE, que siendo una lámpara ocupaba 7 m1. metro.

Para entender la escala. Estadio de wembley. Aproximadamente tanto estaba ocupado por el complejo de máquinas múltiples Elbrus para el sistema de defensa antimisiles A-135.
La CPU de ambas máquinas se basa en una arquitectura de pila CISC con notación polaca inversa. El código de un programa compilado consta de un conjunto de segmentos. Un segmento generalmente corresponde a un procedimiento o bloque en un programa. Cuando comienza la ejecución del programa, se asignan dos ubicaciones de memoria: una para la pila y otra para el diccionario de segmentos, que se utiliza para hacer referencia a múltiples segmentos de programa en la RAM. Las áreas de memoria para segmentos de código y matrices son asignadas por el sistema operativo a pedido.
Los descriptores en ambas máquinas son responsables de la reentrada del código al organizar el intercambio automático de memoria entre subprocesos en ejecución. El código y los datos están estrictamente separados por etiquetas, los descriptores le permiten ejecutar código idéntico en diferentes conjuntos de datos para diferentes usuarios, con la garantía de su protección.
Ambas computadoras incluso usan registros de propósito especial idénticos (por ejemplo, cada máquina tiene registros de base de pila, límite de pila y parte superior de la pila) e instrucciones de administración de pila.
Burroughs y Elbrus tienen una filosofía muy similar, pero difieren mucho en el diseño del propio procesador.
El procesador B6700 consta de un sumador de 48 bits, una unidad de procesamiento de direcciones, siete controladores de funciones (programa, aritmética, cadena, ajuste de pila, interrupción, transferencia y memoria) y un conjunto de registros. Estos últimos incluyen 4 registros de datos de 51 bits (dos elementos de la pila superior, valor actual, valor intermedio) y 48 registros de instrucciones de 20 bits (32 registros de visualización responsables de almacenar puntos de entrada a los procedimientos que se están ejecutando actualmente y 8 registros base cada uno). y registros de índice).
Lo más interesante en el procesador fue un bloque extremadamente complicado, el llamado. controladores de una familia de operaciones (en la cantidad de 10 piezas), que, a partir de los bloques funcionales disponibles, construyeron una tubería computacional para cada comando. Esto permitió reducir significativamente el costo de los transistores.
El controlador pasa la instrucción decodificada al registro de palabra de instrucción de programa actual y selecciona el controlador de familia de operadores apropiado. La característica clave es que las instrucciones se ejecutan estrictamente secuencialmente en el orden dictado por el compilador. Las instrucciones aritméticas no pueden superponerse porque solo hay un sumador en la CPU.
Esta fue la principal diferencia entre el procesador Elbrus. Babayan se golpeó el pecho con orgullo con el puño y declaró "el primer superescalar del mundo en Elbrus" (que no tuvo nada que ver con el desarrollo), pero en la práctica, Burtsev estudió cuidadosamente la arquitectura del gran CDC 6600 para aprender el secretos de interacción entre grupos de bloques funcionales en transportadores paralelos.
Del CDC 6600, Elbrus tomó prestada la arquitectura de varios bloques funcionales (10 en total): sumador, multiplicador, divisor, bloque lógico, bloque de conversión de codificación BCD, bloque de llamada de operandos, bloque de escritura de operandos, bloque de procesamiento de cadenas, bloque de ejecución de subrutinas e indexación. cuadra.
Hay cierta superposición funcional entre estos bloques y los controladores B6700, pero también hay diferencias importantes, por ejemplo, la aritmética en Elbrus tiene 4 grupos independientes en lugar de uno.
Ya se han utilizado múltiples ALU en otras máquinas, pero nunca en el mundo, en un procesador de pila. Naturalmente, esto no se hizo debido a la gran estupidez de los desarrolladores occidentales. La pila, por definición, asume el direccionamiento cero: todos los operandos necesarios deben estar en la parte superior. Obviamente, en ausencia de direcciones tradicionales, solo una operación por ciclo puede abordar correctamente la parte superior; esto básicamente excluye la operación de bloques paralelos.
El grupo de Burtsev tuvo que pervertirse monstruosamente para sortear esta limitación.
De hecho, el procesador de pila B6700 en la versión Elbrus ha dejado de ser un procesador de pila. Los milagros no ocurren y un erizo no se cruza con una serpiente, por lo que la arquitectura interna, invisible para el programador, tuvo que hacerse con un registro clásico. El controlador recibe y decodifica el comando como de costumbre y luego lo convierte al formato de registro interno. B6700 interpretó solo 2 elementos superiores de la pila como registros internos, Elbrus: ¡32 elementos! De hecho, solo queda un nombre de la pila.
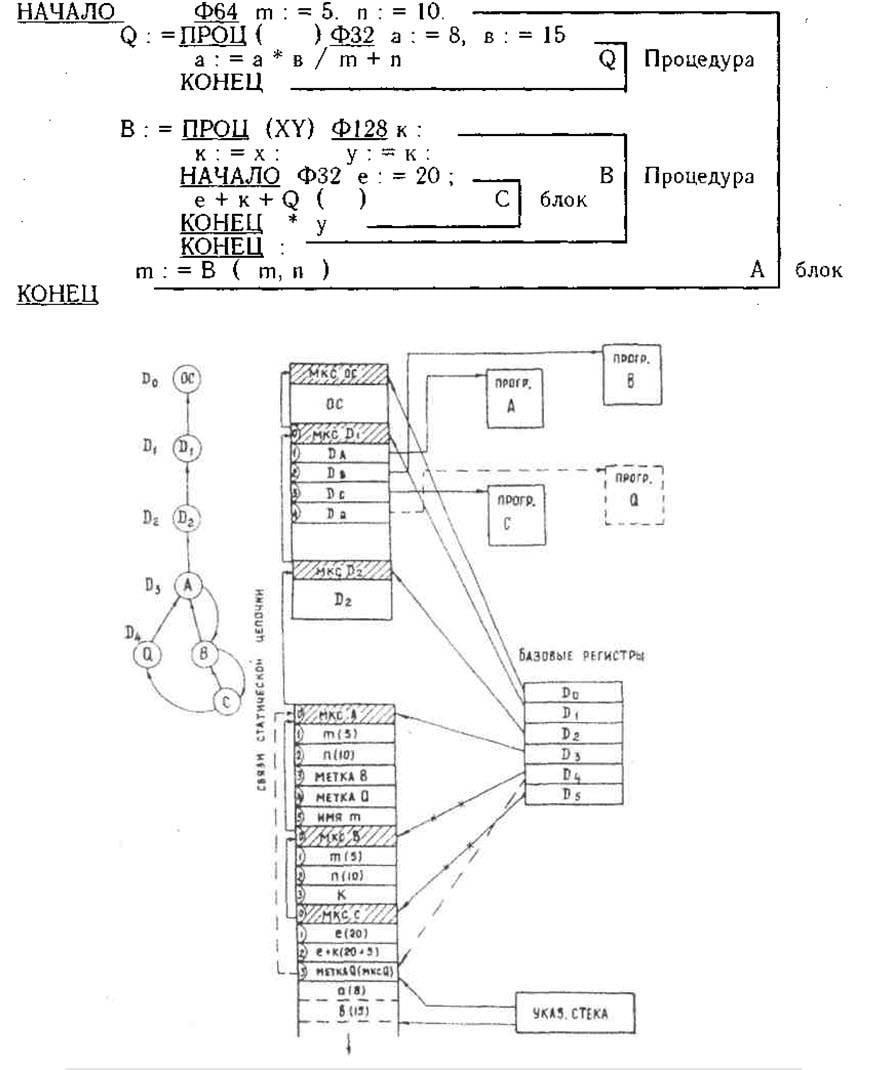
El estado de la pseudopila de Elbrus en el momento de la transición al procedimiento Q. Del artículo de Burtsev "Principios de la construcción de sistemas informáticos multiprocesador Elbrus".
Naturalmente, esto sería completamente inútil si la CU no pudiera cargar todos los dispositivos funcionales en paralelo. Así se desarrolló el mecanismo de ejecución especulativa, que además es absolutamente original.
Las instrucciones de Elbrus se pueden pasar a los bloques de funciones antes de que todos los operandos necesarios estén disponibles; una vez cargados, simplemente esperarán los datos. De hecho, la ejecución ocurre según el principio de la arquitectura de flujo de datos, el orden exacto de ejecución depende del orden en que los operandos estén disponibles.
¿Qué lograron al final?
Bueno, la reacción de un programador moderno ante decisiones tan salvajes es obvia:
Recuerdo que trabajar con arreglos me mató. Cambiar al modo de supervisor para asignar una matriz, ¿es eso normal? ¿Es normal que la canalización de ejecución conozca las matrices? Trabajar con matrices a través de un descriptor, ¿es eso eficiente? Escribir fuera de los límites es más rápido de verificar, ¿verdad? Da miedo imaginar cómo este horror caerá sobre el equipo. Sin embargo, entonces había un diseño diferente con latencia y velocidad de memoria y otros componentes, para nada igual que ahora. Ella podría justificar movimientos tan audaces, pero tales diseños no viven, de ninguna manera. De hecho, no sobrevivieron...
Teóricamente, los desarrolladores de máquinas de etiquetas puras partieron del hecho de que a mediados de la década de 1970 todavía no había arquitecturas y compiladores capaces de al menos alguna paralelización automática de código, como resultado de lo cual, la mayoría de los sistemas multiprocesador no podían cargarse de manera eficiente. completamente, y las unidades de ejecución a menudo estaban inactivas. La salida de este callejón sin salida era la arquitectura superescalar o las notorias máquinas VLIW, pero aún quedaban lejos (aunque el primer procesador superescalar lo usó el mismo Cray en el CDC6600 allá por 1965, aquí todavía no huele a producción en masa ). Y así nació la idea de facilitar el trabajo de un programador trasladando la arquitectura a un lenguaje Java. Sin embargo, vale la pena señalar que no es fácil hacer un buen superescalar en una arquitectura de pila; es mucho más fácil hacerlo para los sistemas de instrucción RISC. Veamos qué tipo de superescalar hay en Elbrus-2: “La tasa de procesamiento de comandos en el dispositivo de control puede variar de dos comandos para 1 ciclo a un comando para 3 ciclos. Las combinaciones de comandos más comunes se procesan a la velocidad máxima: leer el valor y el comando aritmético; carga la dirección y toma el elemento de la matriz; descarga la dirección y anótala".
Como resultado, tenemos lo que tenemos: un superescalar para dos instrucciones por ciclo de reloj y las instrucciones más primitivas. No hay nada de qué enorgullecerse aquí, es bueno que al menos sepan cómo combinar la lectura de datos con la aritmética (y solo cuando ingresan al caché).
Teóricamente, los desarrolladores de máquinas de etiquetas puras partieron del hecho de que a mediados de la década de 1970 todavía no había arquitecturas y compiladores capaces de al menos alguna paralelización automática de código, como resultado de lo cual, la mayoría de los sistemas multiprocesador no podían cargarse de manera eficiente. completamente, y las unidades de ejecución a menudo estaban inactivas. La salida de este callejón sin salida era la arquitectura superescalar o las notorias máquinas VLIW, pero aún quedaban lejos (aunque el primer procesador superescalar lo usó el mismo Cray en el CDC6600 allá por 1965, aquí todavía no huele a producción en masa ). Y así nació la idea de facilitar el trabajo de un programador trasladando la arquitectura a un lenguaje Java. Sin embargo, vale la pena señalar que no es fácil hacer un buen superescalar en una arquitectura de pila; es mucho más fácil hacerlo para los sistemas de instrucción RISC. Veamos qué tipo de superescalar hay en Elbrus-2: “La tasa de procesamiento de comandos en el dispositivo de control puede variar de dos comandos para 1 ciclo a un comando para 3 ciclos. Las combinaciones de comandos más comunes se procesan a la velocidad máxima: leer el valor y el comando aritmético; carga la dirección y toma el elemento de la matriz; descarga la dirección y anótala".
Como resultado, tenemos lo que tenemos: un superescalar para dos instrucciones por ciclo de reloj y las instrucciones más primitivas. No hay nada de qué enorgullecerse aquí, es bueno que al menos sepan cómo combinar la lectura de datos con la aritmética (y solo cuando ingresan al caché).
En principio, la URSS en este sentido se derrotó a sí misma, las máquinas de Burroughs, como ya se mencionó, no prescindieron de tales adornos, no por la estupidez de sus arquitectos. Querían hacer una arquitectura de pila pura y lo hicieron bien.
En Elbrus quedó un nombre de la elegante sencillez de la pila, mientras que la máquina se volvió un orden de magnitud más cara y más complicada (qué diablos fue depurar el procesador de Elbrus, el que lo hizo nos lo dirá más adelante), pero en rendimiento todavía no ganó realmente: recibió una combinación de deficiencias de ambas clases de máquinas.
En general, este es el caso cuando sería mejor robar la idea tal como es, sin tratar de sovietizarla, es decir, expandirla y profundizarla.
¿Qué había acerca de las matrices?
Burtsev también puso aquí sus 5 kopeks.
En el Burroughs B6700, se accede indirectamente a todos los elementos de la matriz mediante la indexación a través del descriptor de la matriz. Esto requiere un ciclo adicional. En Elbrus, decidieron eliminar este ciclo y agregaron un bloque de hardware para precargar elementos de matriz en el caché local. El bloque de índice contiene memoria asociativa, que almacena la dirección del elemento actual junto con el paso en la memoria.
Como resultado, solo se necesita el asa para extraer el primer elemento de la matriz; todos los demás pueden ser contactados directamente. La memoria asociativa puede almacenar información sobre seis arreglos, y calcular la dirección de un elemento en un ciclo toma solo un ciclo, los elementos del arreglo para incluso 5 iteraciones del ciclo se pueden extraer por adelantado.
Con esta innovación, los desarrolladores lograron una aceleración significativa de las operaciones vectoriales en Elbrus en comparación con el B6700, que se construyó como una máquina puramente escalar.
La arquitectura de la memoria también ha sufrido cambios significativos.
El B6700 no tenía caché, solo un conjunto local de registros de propósito especial. En Elbrus, el caché consta de cuatro secciones separadas: un búfer de instrucciones (512 palabras) para almacenar las instrucciones ejecutadas por el programa, un búfer de pila (256 palabras) para almacenar la parte más activa (superior) de la pila, que de otro modo se almacena en la memoria principal; búfer de matriz (256 palabras) para almacenar elementos de matriz que se procesan en ciclos; memoria asociativa para datos globales (1 palabras) para datos distintos de los almacenados en otros búferes. Esto incluye variables globales de programa, identificadores y datos locales de procedimientos que no caben en el búfer de pila.
Esta organización de caché hizo posible incluir efectivamente una cantidad relativamente grande de procesadores en una configuración de memoria compartida.
¿Cuál es el problema de atornillar el caché a un sistema multiprocesador?
El hecho es que cada procesador puede tener su propia copia local de los datos, pero si queremos obligar a los procesadores a procesar una tarea en paralelo, debemos asegurarnos de que los contenidos de los cachés sean idénticos.
Tal verificación se llama mantener la coherencia de la memoria caché y requiere numerosos accesos a la RAM, lo que ralentiza terriblemente el sistema y acaba con la idea. Es por eso que la cantidad de procesadores en la arquitectura SMP, el multiprocesamiento simétrico, rara vez supera las 4 piezas (incluso ahora, 4 es la cantidad máxima clásica de zócalos en una placa base de servidor).
El mainframe de procesador dual IBM 3033 (1978) utilizó un diseño simple de almacenamiento directo en el que los datos cambiados en la memoria caché se actualizan inmediatamente en la RAM.
El IBM 3084 (1982, 4 procesadores) utilizó un esquema de coherencia más avanzado en el que la transferencia de datos a la RAM podía retrasarse hasta que se sobrescribieran las entradas de caché o hasta que otro procesador accediera a las entradas de datos correspondientes en la memoria principal.
Es por eso que el B3 de 6700 procesadores prescindió de un caché: sus procesadores ya eran demasiado sofisticados.
La coherencia de caché en Elbrus se mantuvo mediante el uso del concepto de una sección crítica en un programa, que es bien conocido por los arquitectos de sistemas operativos. Las partes del programa que acceden a los recursos (datos, archivos, periféricos) compartidos por varios procesadores configuran un semáforo especial en el momento del acceso, lo que significa ingresar a la sección crítica, luego de lo cual el recurso se bloqueó para todos los demás procesadores. Después de dejarlo, el recurso se desbloqueó nuevamente.
Dado que las secciones críticas representaron (al menos según el desarrollador) alrededor del 1 % del programa promedio, el 99 % del tiempo compartido de caché no incurrió en la sobrecarga de mantener la coherencia. Las instrucciones en un búfer de instrucciones son, por definición, estáticas, por lo que sus copias en varios cachés siguen siendo idénticas. Esta es una de las razones por las que Elbrus admite hasta 10 procesadores.
En general, su arquitectura es un ejemplo de un uso muy temprano de un caché segmentado, un principio similar (búfer de pila, búfer de instrucciones y búfer de memoria asociativa) ya se implementó en el B7700, pero salió en 1976, cuando la mayoría de los se completó el trabajo para crear la arquitectura de Elbrus.
Así, Elbrus recibe merecidamente el título de uno de los primeros sistemas de propósito general del mundo con memoria compartida por 10 procesadores.
Técnicamente (teniendo en cuenta el hecho de que Elbrus-2 funcionó normalmente solo en 1989), la primera supercomputadora de este tipo lanzada fue la Sequent Balance 8000 con 12 procesadores National Semiconductor NS32032 (1984; la versión Balance 1986 con 21000 procesadores fue lanzada en 30 ), pero la idea misma se le ocurrió al grupo de Burtsev definitivamente diez años antes.
El modelo de memoria de Elbrus fue extremadamente efectivo.
Por ejemplo, la ejecución de un programa simple del estilo de sumar varios números con reasignación requerida en el caso de S/ 360 de 620 accesos de memoria (si está escrito en ALGOL) a 46 (si está escrito en ensamblador), 396 y 54 en el caso de BESM-6 y sólo 23 en "Elbrus".
Al igual que las máquinas de Burroughs, Elbrus usa etiquetas, pero su uso se ha ampliado muchas veces.
En su afán por transferir el mayor control posible al hardware, el grupo de Burtsev duplicó la longitud de la etiqueta a 6 bits. Como resultado, la máquina pudo distinguir entre operandos de precisión media/simple/doble, enteros/números reales, palabras vacías/completas, etiquetas (incluidas cosas especializadas como "etiqueta privilegiada sin bloque de interrupción externo" y "etiqueta sin información de dirección"). grabadora"), semáforos, palabras de control y otros.
Uno de los principales objetivos de la creación de etiquetas era simplificar la programación. Si los bloques de funciones pudieran distinguir entre operandos reales y enteros, podrían diseñarse para adaptarse a los cálculos en cualquiera, y no habría necesidad de bloques escalares y reales separados.
De hecho, Elbrus implementó la tipificación dinámica a un nivel comparable al OOP moderno y en hardware.
Otro propósito de las etiquetas era detectar errores, como un intento de realizar una operación aritmética en una instrucción, las etiquetas también podrían usarse para proteger la memoria, restringir la escritura de ciertos datos, etc.
En el campo de las etiquetas, Elbrus ha llevado las ideas de la máquina base y la B6700 a un nuevo nivel de sofisticación.
Todo esto hizo posible lograr lo que los arquitectos de Burroughs no lograron. Como recordamos, necesitaban extensiones ALGOL separadas para escribir el código del sistema operativo y la administración posterior del sistema. Los desarrolladores de "Elbrus" abandonaron esta idea y crearon un único lenguaje universal completo "El-76", en el que se podía escribir todo.
Para escribir un sistema operativo completo en un lenguaje de alto nivel (incluido el código responsable de las cosas internas de nivel más bajo, como la asignación de memoria y la conmutación de procesos), se requiere hardware especial de muy alto nivel. Por ejemplo, la conmutación de procesos en Elbrus OS se implementó como una secuencia de operadores de asignación que realizan acciones bien definidas en registros de hardware especiales.
El diseño de la memoria RAM en ambas máquinas es extremadamente similar, aunque Elbrus (especialmente en la segunda versión) contiene mucha más memoria.
La RAM "Elbrus" está organizada jerárquicamente, la sección de memoria (1 gabinete) consta de 4 módulos, cada módulo consta de 32 bloques de 16 palabras. La alternancia es posible en varios niveles: entre secciones, entre módulos dentro de una sección y dentro de módulos individuales. Se pueden leer hasta cuatro palabras de cada módulo de memoria en un ciclo. El ancho de banda máximo de la memoria es de 450 MB/s, aunque la velocidad máxima de transferencia de datos con cada procesador es de 180 MB/s.
Los esquemas de administración de memoria en B6700 y Elbrus son generalmente muy similares. La memoria está organizada en segmentos de longitud variable que representan secciones lógicas de un programa según lo define el compilador. Según la división lógica del programa, los segmentos pueden tener diferentes niveles de protección y ser compartidos entre procesos.
En el B6700, los segmentos se movían entre el almacenamiento principal y el virtual como un todo. Las matrices fueron la excepción. Podrían almacenarse en la memoria principal en grupos de 256 palabras cada uno, delimitados en ambos lados por palabras de enlace.
En Elbrus, los segmentos de código se tratan de manera diferente a los segmentos de datos y matrices. El código se procesa de la misma manera que en el B6700 y los datos y las matrices se organizan en páginas de 512 palabras cada una.
El enfoque de Elbrus es más eficiente aquí y permite un intercambio más rápido.
Además, Elbrus utiliza un tipo de memoria virtual más moderno.
En las computadoras Burroughs, el direccionamiento estaba limitado a 20 bits o 220 palabras, la memoria física máxima en el B6700/7700. La presencia de segmentos en la memoria principal se indicaba mediante un bit especial en su descriptor, que permanecía en la RAM durante la ejecución del proceso. No existía el concepto de un verdadero espacio de memoria virtual que fuera mayor que la cantidad total de memoria física; los descriptores contenían solo direcciones físicas.
Las máquinas Elbrus usaban un esquema de direccionamiento de 20 bits similar para los segmentos del programa, pero se usaba el direccionamiento de 32 bits para los segmentos de datos y matrices de constantes. Esto proporcionó un espacio de memoria virtual de 232 bytes (4 gigabytes). Estos segmentos se movieron entre la memoria virtual y física utilizando un mecanismo de paginación que utilizó las tablas de paginación almacenadas en el bloque asociativo de memoria de paginación para convertir entre direcciones virtuales y físicas. Las direcciones virtuales constan de un número de página y un desplazamiento dentro de la página. Esta es en realidad una implementación moderna y completa de la memoria virtual, al igual que en las máquinas IBM.
Entonces, ¿cuál es nuestro veredicto?
Elbrus definitivamente no era un clon completo de Burroughs B6700 (e incluso B7700).
Además, ni siquiera era su clon ideológico, sino su hermano, porque tanto el B6700 como Elbrus se inspiraron en la misma fuente: el trabajo de Ailif sobre la máquina base y los trabajos de la Universidad de Manchester, y el ancestro común del B. La serie en sí, el famoso B5000, fue un desarrollo de las ideas plasmadas en el automóvil R1 de Rice. Además, Elbrus usó el CDC 6600 como inspiración (donde sin él) y en términos de trabajar con memoria virtual: IBM S / 360 modelo 81.
En este sentido, sin duda, admitimos que la arquitectura de Elbrus en sí estaba absolutamente en la tendencia de los desarrollos mundiales de la década de 1970 y era un digno representante de ellos.
Además, en muchos aspectos era mucho más avanzada que la B6700/7700.
Quizás solo los intentos de lograr el superescalarismo pueden reconocerse como una decisión realmente fallida, que fracasó tanto en términos de arquitectura (un superescalar para 2-3 operaciones, como ya se mencionó, no vale la pena) como práctico (como resultado, el ya monstruosamente un procesador complejo se volvió aún más complejo, ocupando un enorme gabinete en forma de T y casi imposible de depurar, razón por la cual fue tratado durante tantos años) puntos de vista.
Desafortunadamente, para pasar por alto esos momentos, uno debe tener una experiencia e intuición colosales, desarrolladas a lo largo de años de trabajo con los mejores ejemplos de arquitectura del mundo, que, por supuesto, no estaba en la Unión.
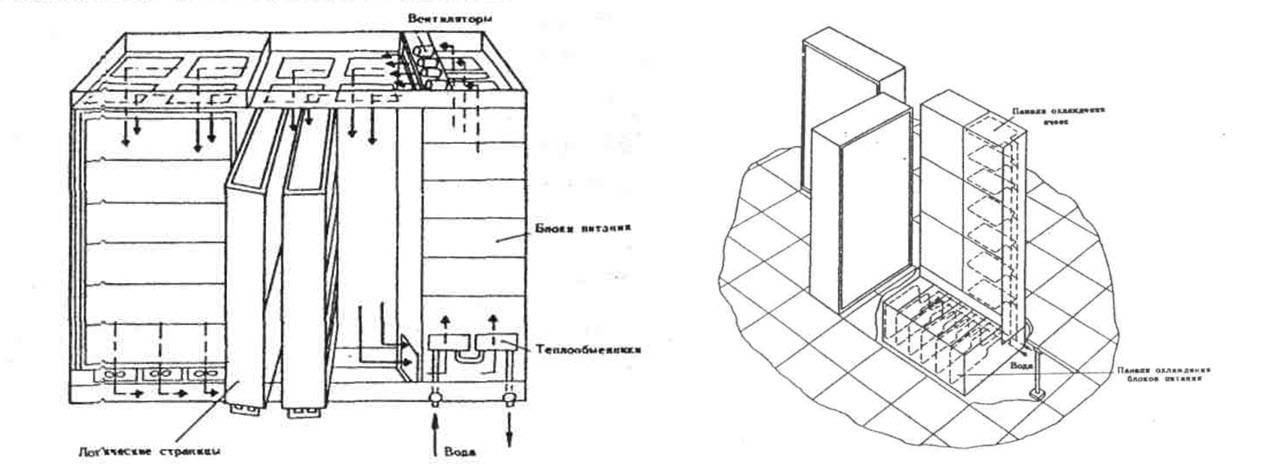
Gabinete típico "Elbrus-1" y CPU "Elbrus-2" del artículo de Burtsev "Paralelismo de procesos informáticos y desarrollo de arquitectura de supercomputadora". MVC "Elbrús".
Naturalmente, no se debe hablar de ninguna originalidad de Elbrus; de hecho, fue solo una compilación de varias soluciones técnicas, mejoradas significativamente en algunos aspectos.
Pero desde este punto de vista, la B5000 también era una versión muy avanzada de la R1, como ya hemos dicho.
Tampoco hay dudas sobre la relevancia de tal arquitectura ahora: la década de 1970 quedó atrás, la historia de TI ha cambiado en una dirección completamente diferente y ha estado yendo allí durante 40 años.
Entonces, en papel, "Elbrus" según los estándares de 1970 fue, sin subestimar, una obra maestra, bastante comparable a los mejores autos occidentales. Y aquí está su implementación...
Sin embargo, este es un tema para el próximo artículo.
To be continued ...
información